Comprehensive NLP Pipeline Guide
Based on the latest research and industry practices from 2024-2025, here's a complete guide to building robust Natural Language Processing pipelines.
Based on the latest research and industry practices from 2024-2025, here's a complete guide to building robust Natural Language Processing pipelines.
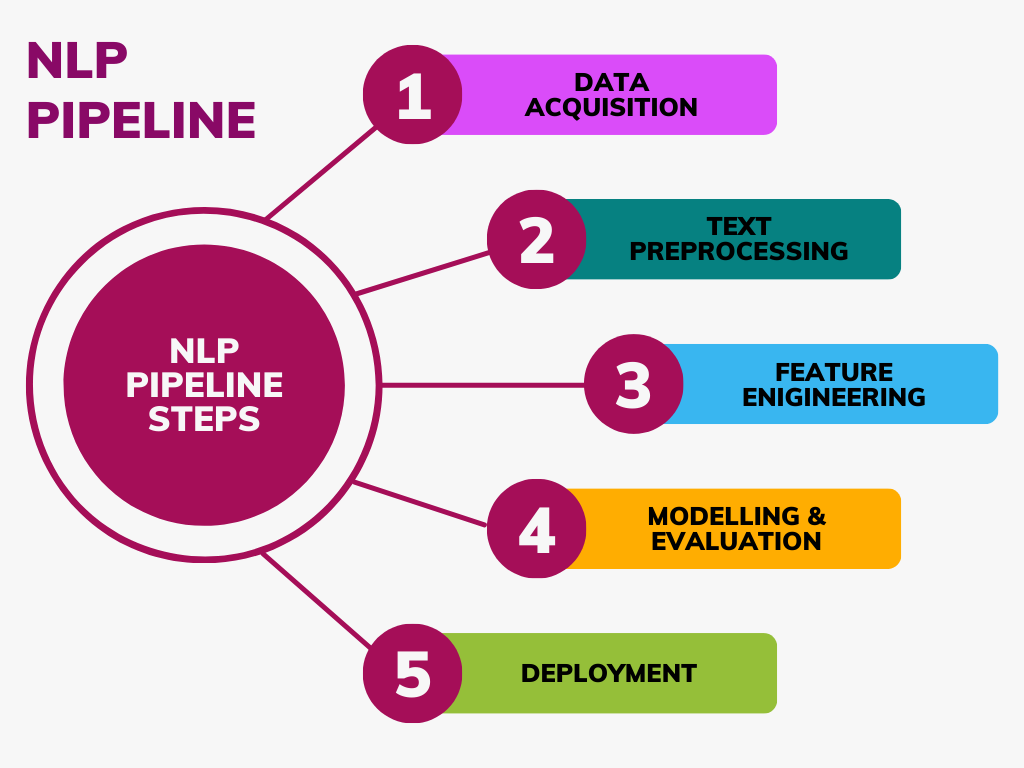
The NLP pipeline is a systematic sequence of processes that transform raw text data into meaningful insights and applications. Unlike traditional ML pipelines, NLP pipelines require specialized text processing steps to convert human language into machine-readable formats.
Obtaining quality text data from various sources including databases, web scraping, APIs, and document extraction.
Cleaning and normalizing raw text through tokenization, lowercasing, stop word removal, and stemming/lemmatization.
Transforming text into numerical representations using BoW, TF-IDF, n-grams, and modern word embeddings.
Choosing appropriate models from rule-based systems, traditional ML, deep learning, or cloud APIs.
Deploying models with container orchestration, API frameworks, and implementing monitoring and maintenance.
The foundation of any NLP system starts with obtaining quality text data:
Critical phase for preparing raw text for analysis:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
bow_matrix = vectorizer.fit_transform(documents)from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
tfidf_matrix = tfidf.fit_transform(documents)# Capture phrase-level information
ngram_vectorizer = CountVectorizer(ngram_range=(1, 3))
ngram_matrix = ngram_vectorizer.fit_transform(documents)
Overall correctness of predictions
True positives / (True positives + False positives)
True positives / (True positives + False negatives)
Harmonic mean of precision and recall
Area under the curve for binary classification
For named entity recognition tasks
For POS tagging and similar tasks
Bilingual evaluation understudy for translation quality
Recall-oriented understudy for gisting evaluation
Language model quality measure - lower is better
Measure ROI, user engagement, conversion rates, and other key performance indicators that demonstrate the business value of the NLP system.
Evaluate performance based on specific task outcomes such as customer satisfaction scores, support ticket resolution rates, or sales conversion improvements.
Conduct usability testing, collect user feedback, perform A/B testing, and measure user satisfaction to ensure the system meets user needs and expectations.
Use Docker for containerization and Kubernetes for orchestration to ensure scalability, reliability, and easy deployment across different environments.
Build RESTful APIs using FastAPI (recommended for performance), Flask (for simplicity), or Django REST framework (for complex applications) to expose your NLP models.
Utilize specialized model serving solutions like TensorFlow Serving for TensorFlow models, TorchServe for PyTorch models, or ONNX Runtime for cross-framework deployment.
Deploy on managed ML platforms like AWS SageMaker, Google AI Platform, or Azure ML for simplified infrastructure management, auto-scaling, and integrated monitoring.
Track key metrics including latency (response time), throughput (requests per second), error rates, and accuracy drift over time to ensure consistent performance.
Implement systems to detect changes in input data distribution that could degrade model performance, including concept drift and feature drift.
Use ML lifecycle management tools like MLflow, Weights & Biases, or Neptune to track model versions, parameters, metrics, and artifacts for reproducibility.
Implement gradual rollout strategies and A/B testing to compare new model versions against baselines, ensuring improvements before full deployment.
Production-Ready NLP with industrial-strength processing and built-in trained models.
import spacy
# Load pre-trained model
nlp = spacy.load("en_core_web_sm")
# Process text
doc = nlp("Apple Inc. is looking at buying U.K. startup for $1 billion")
# Extract entities, POS tags, dependencies
for ent in doc.ents:
print(ent.text, ent.label_)Educational & Research toolkit with comprehensive algorithms and datasets.
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
# Download required data
nltk.download('punkt')
nltk.download('stopwords')
# Basic preprocessing
tokens = word_tokenize(text)
stop_words = set(stopwords.words('english'))
filtered_tokens = [w for w in tokens if w.lower() not in stop_words]State-of-the-art models with access to latest transformers and easy fine-tuning.
from transformers import pipeline, AutoTokenizer, AutoModel
# Pre-built pipelines
classifier = pipeline("sentiment-analysis")
result = classifier("I love this NLP pipeline!")
# Custom model loading
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModel.from_pretrained("bert-base-uncased")# Example comprehensive NLP pipeline
class NLPPipeline:
def __init__(self):
self.preprocessor = TextPreprocessor()
self.vectorizer = TfidfVectorizer()
self.model = BertForSequenceClassification()
def preprocess(self, text):
# Clean and normalize text
cleaned = self.preprocessor.clean(text)
# Tokenize and vectorize
features = self.vectorizer.transform([cleaned])
return features
def predict(self, text):
features = self.preprocess(text)
prediction = self.model.predict(features)
return prediction
def train(self, texts, labels):
processed_texts = [self.preprocess(text) for text in texts]
self.model.fit(processed_texts, labels)Raw Text → Preprocessing → Feature Extraction → Classification Model → PredictionRaw Text → Tokenization → POS Tagging → NER Model → Entity ExtractionPrompt → Tokenization → Language Model → Token Generation → Text DecodingSource Text → Tokenization → Encoder → Decoder → Target Text GenerationQuestion + Context → Tokenization → BERT Model → Answer Span ExtractionThe NLP pipeline landscape continues to evolve rapidly with transformer models and large language models reshaping the field.
GPT-4, Claude, Gemini integration for enhanced capabilities and zero-shot learning.
Integration of text, vision, and audio processing for comprehensive understanding.
MobileBERT, DistilBERT for edge deployment and low-resource environments.
Models that work without task-specific training, adapting to new domains instantly.
Privacy-preserving distributed training across multiple devices and locations.
Begin with rule-based approaches, then progress to ML/DL as needed.
Clean, relevant data is more important than complex models.
spaCy for production, NLTK for learning, Transformers for SOTA.
Track performance and adapt to changing data distributions.
Design with production requirements in mind from the beginning.